
 As Samsung continues to pioneer premium mobile AI experiences, we visit Samsung Research centers around the world to learn how Galaxy AI is enabling more users to maximize their potential. Galaxy AI now supports 16 languages, so more people can expand their language capabilities, even when offline, thanks to on-device translation in features such as Live Translate, Interpreter and Note Assist. But what does AI language development involve? This series examines the challenges of working with mobile AI and how we overcame them. First up, we head to Indonesia to learn where one begins teaching AI to speak a new language.
As Samsung continues to pioneer premium mobile AI experiences, we visit Samsung Research centers around the world to learn how Galaxy AI is enabling more users to maximize their potential. Galaxy AI now supports 16 languages, so more people can expand their language capabilities, even when offline, thanks to on-device translation in features such as Live Translate, Interpreter and Note Assist. But what does AI language development involve? This series examines the challenges of working with mobile AI and how we overcame them. First up, we head to Indonesia to learn where one begins teaching AI to speak a new language.
 The first step is establishing targets, according to the team at Samsung R&D Institute Indonesia (SRIN). “Great AI begins good quality and relevant data. Each language demands a different way to process this, so we dive deep to understand the linguistic needs and the unique conditions of our country,” says Junaidillah Fadlil, head of AI at SRIN, whose team recently added Bahasa Indonesia (Indonesian language) support to Galaxy AI. “Local language development has to be led by insight and science, so every process for adding languages to Galaxy AI starts with us planning what information we need and can legally and ethically obtain.”
The first step is establishing targets, according to the team at Samsung R&D Institute Indonesia (SRIN). “Great AI begins good quality and relevant data. Each language demands a different way to process this, so we dive deep to understand the linguistic needs and the unique conditions of our country,” says Junaidillah Fadlil, head of AI at SRIN, whose team recently added Bahasa Indonesia (Indonesian language) support to Galaxy AI. “Local language development has to be led by insight and science, so every process for adding languages to Galaxy AI starts with us planning what information we need and can legally and ethically obtain.”
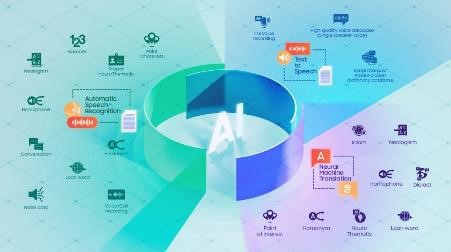
Galaxy AI features such as Live Translate perform three core processes: automatic speech recognition (ASR), neural machine translation (NMT) and text-to-speech (TTS). Each process needs a distinct set of information.
ASR, for instance, needs extensive recordings of speech in numerous environments, each paired with an accurate text transcription. Varying background noise levels help account for different environments. “It’s not enough just to add noises to recordings,” explains Muchlisin Adi Saputra, the team’s ASR lead. “In addition to the language data we obtained from authorized 3rd party partners, we must go out into coffee shops or working environments to record our own voices. This allows us to authentically capture unique sounds from real life, like people calling out or the clattering of keyboards.”
The ever-changing nature of languages must also be considered. Saputra adds: “We need to keep up to date with the latest slang and how it is used, and mostly we find it on social media!”
Next, NMT requires translation training data. “Translating Bahasa Indonesia is challenging,” says Muhamad Faisal, the team’s NMT lead. “Its extensive use of contextual and implicit meanings relies on social and situational cues, so we need numerous translated texts that the AI could reference for new words, foreign words, proper nouns, and idioms – any information that helps AI understand the context and rules of communication.”
TTS then requires recordings that cover a range of voices and tones, with additional context on how parts of words sound in different circumstances. “Good voice recordings could do half the job and cover all the required phonemes (units of sound in speech) for the AI model,” adds Harits Abdurrohman, TTS lead. “If a voice actor did a great job in the earlier phase, the focus shifts to refining the AI model to clearly pronounce specific words.”
Stronger Together
It takes vast resources to plan for much data, and SRIN worked closely with linguistics experts. “This challenge requires creativity, resourcefulness and expertise in both Bahasa Indonesia and machine learning,” Fadlil reflects. “Samsung’s philosophy of open collaboration played a big part in getting the job done, as did our scale of operations and history of AI development.”
Working with other Samsung Research centers around the world, the SRIN team was able to quickly adopt best practices and overcome the complexities of establishing data targets. Furthermore, collaboration was good for advancing not only technology but also culture. When the SRIN team joined their counterparts in Bangalore, India, they observed the local fasting customs, creating deeper connections and expanding their understanding of different cultures.
For the team, Galaxy AI’s language expansion project took on a new significance. “We are particularly proud of our achievements here as this was our first AI project, and it won’t be our last as we continue to refine our models and improve the quality of output,” Fadlil concludes. “This expansion not only reflects our values of openness but also respects and incorporates our cultural identities through language.”
In the next episode of The Learning Curve, we will head to Samsung R&D Institute Jordan to speak to the team who led Galaxy AI’s Arabic language project. Tune in to learn about the complexities of building and training an AI model for a language with diverse dialects.
